
.svg)
Siła płynąca z danych
Dane bez analityki są jak Bentley bez silnika. To tylko nic nie znaczące liczby, jeszcze nie potężna wiedza. A te liczby mogą cię oszukiwać - i to w taki sposób, że możesz stracić czas i pieniądze, a nawet zrujnować swoją firmę.

Co musimy wziąć pod uwagę podczas budowania silnej strategii marketingowej, zwłaszcza w nieprzewidywalnym świecie VUCCA?
Zabiorę Cię w krótką podróż, w której spotkamy trzech bohaterów, którzy pomogą nam wykryć typowe błędy w analityce danych.
Od dzisiaj, gdy zobaczysz Homera Simpsona, hipsterską dziewczynę lub Franka Underwooda, będą ci przypominać o błędach (lub paradoksach) związanych z analizą danych.
Zacznijmy więc od historii Homera - a może nie tyle jego historii, co naszej.
Czego Homer Simpson może Cię nauczyć na temat interpretacji trendów danych?
Był słoneczny poranek zeszłej wiosny, około połowy kwietnia. Poniedziałek - „najlepszy” dzień, w którym wszyscy są bardzo zajęci.
Nadszedł czas, aby podsumować poprzedni tydzień, i odbyło się spotkanie wykonawcze. Dostarczyliśmy cotygodniowy raport obejmujący wyniki według wstępnie ustawionych wskaźników KPI.
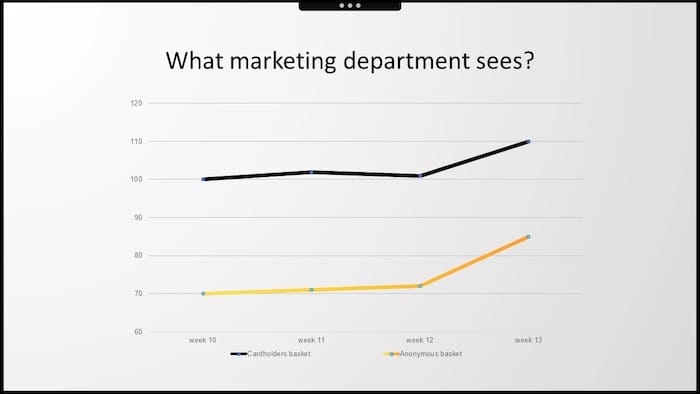
Zespół każdego działu przyniósł swoje slajdy i omówił trendy rynkowe. Wśród wielu KPI, które dostarczyliśmy, były dwa, które przyciągnęły wiele uwagi.
Były to średni koszyk posiadaczy kart lojalnościowych i średnia kwota wydana we wszystkich pozostałych anonimowych transakcjach, w których nie pokazano żadnej karty. Ucieszyliśmy się, bo w 13 tygodniu roku wartości zarówno koszykó anonimowych, jak i lojalnościowych, znacznie wzrosły.
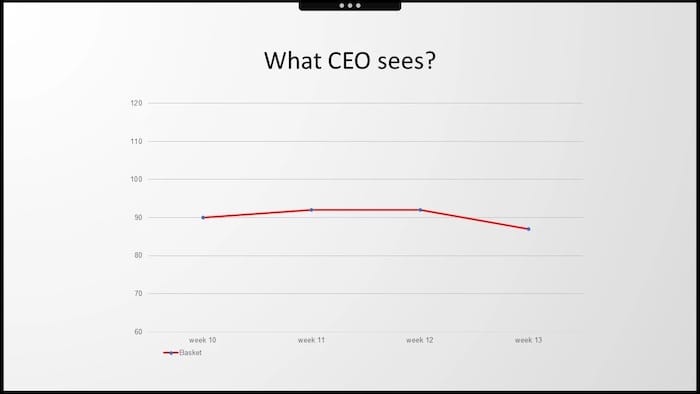
Ale potem dyrektor generalny naszego klienta przedstawił swój slajd. Był mocno rozczarowany patrząc na tydzień 13. Skupił się na prezentowanym wskaźniku z globalnego punktu widzenia, który w jego roli zawsze jest niezbędny - średniej wartości koszyka.
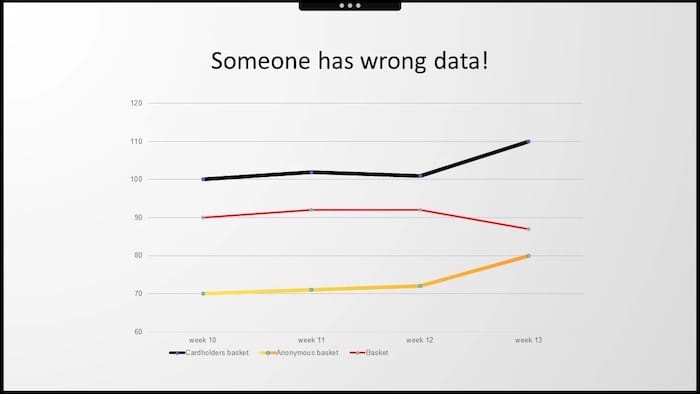
Kiedy spojrzeliśmy na oba wykresy, wydawało się oczywiste, że coś jest strasznie nie tak z danymi. Ktoś na pewno zepsuł raport. Nadszedł czas, aby przerwać spotkanie i wrócić do rozmowy, kiedy my - jako agencja pracująca na tych danych - dostarczymy dokument, który nie będzie sprzeczny z wewnętrznymi danymi firmy.
To ja odebrałem telefon, który stawiał naszą współpracę pod dużym znakiem zapytania. Słuchałem uważnie i natychmiast przeprosiłem, ponieważ pomyślałem, że musiał to być błąd w raporcie.
Potem zaczęliśmy to weryfikować. Otworzyliśmy plik. Mamy surowe dane. Ponownie przeliczyliśmy wszystko, i gdy ponownie spojrzeliśmy głębiej, tym bardziej wszystko wydawało się poprawne.
Okazało się, że nie byliśmy jedynymi, którzy przeżyli ten „WTF” moment.

Podobna sytuacja przytrafiła się brytyjskim uczonym, którzy w 1988 roku opublikowali wyniki swoich badań porównujących metody leczenia kamieni nerkowych. Ich celem było sprawdzenie, czy któryś ze sposobów jest lepszy w leczeniu określonych rodzajów kamieni nerkowych.
Odkryli, co jest oczywiste patrząc na tę tabelę, że leczenie A było lepsze w obu grupach - zarówno w leczeniu małych, jak i dużych kamieni nerkowych. Ale kiedy połączyli obie grupy, leczenie B wydawało się działać lepiej.
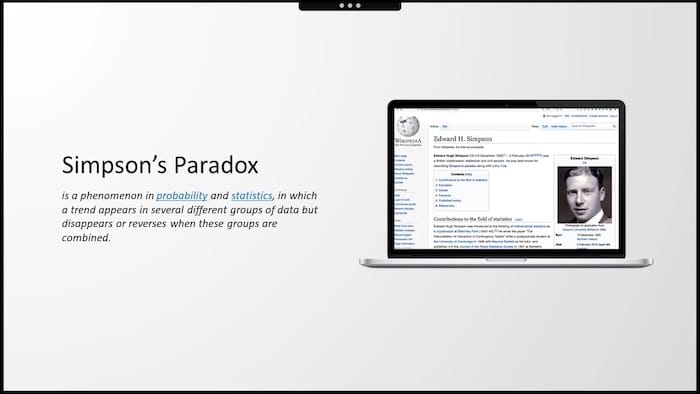
To zjawisko odwracania trendu, który pojawia się w podgrupach i znika po połączeniu tych grup, nazywa się paradoksem Simpsona.
Po raz pierwszy został opisany na początku lat pięćdziesiątych przez brytyjskiego statystyka Edwarda Hugh Simpsona. Karierę rozpoczął jako łamacz kodu w Bletchley Park, gdzie wraz z Alanem Turingiem pracował nad kodem enigmy.
Więc ilekroć znowu zobaczysz Homera Simpsona, pomyśl o Edwardzie Simpsonie, lub przynajmniej o paradoksie Simpsona. To zjawisko tłumaczy dlaczego w naszym przypadku obie wartości koszyka (z/bez karty) wzrosły. Ale ponieważ udział transakcji bez karty znacznie wzrósł, średni wynik koszyka w całości - spadł.
Pozwól, że zabiorę cię w następną podróż z inną bohaterką - Lindą.
Czego hipsterska dziewczyna może cię nauczyć o testowaniu próbek danych?
Linda ma 31 lat. Jest samotna, szczera, bardzo bystra, i specjalizuje się w filozofii. Jako studentka była głęboko zaniepokojona kwestiami dyskryminacji i sprawiedliwości społecznej. Aktywnie uczestniczyła również w demonstracjach antynuklearnych.
Patrząc na ten opis, które stwierdzenie jest bardziej prawdopodobne?
A. Linda jest kasjerką.
B. Linda jest kasjerką bankową i jest aktywna w ruchu feministycznym.
85% osób przedstawionych w historii Lindy stwierdziło, że jest bardziej prawdopodobne, że była zarówno kasjerką bankową, jak i aktywną feministką, co jest trochę sprzeczne z intuicją, prawda?
Ponieważ patrząc na te dwie grupy, grupa kasjerów bankowych musi być większa lub, w ściśle matematycznym sensie, nie mniejsza niż grupa kasjerów bankowych, którzy również są aktywni w ruchu feministycznym - jak na przedstawionym schemacie.

Daniel Kahneman, który współpracował ze swoim przyjacielem Amosem Tverskym, stworzył taki eksperyment i zbadał uprzedzenia i błędy generowane w ludzkim umyśle. Więc jeśli nie czytałeś ”Szybkiego i powolnego myślenia”, książki która podsumowuje ich naukową ścieżkę do Nagrody Nobla w dziedzinie ekonomii, zdecydowanie polecam.
Co to ma wspólnego z analizą danych lojalnościowych? Dwie rzeczy na pewno. Wraz z rosnącą liczbą wymiarów ludzie mają tendencję do włączania wszystkich możliwych zmiennych w modelach. Są raczej podejrzliwi, gdy próbujemy uprościć model.
Wielu naszych klientów czuje potrzebę posiadania zbyt skomplikowanych pulpitów nawigacyjnych i wyjaśnień danych. Wielu menedżerów lojalnościowych czerpie niezdrową przyjemność z dzielenia zbiorów danych na wiele segmentów i wyciągania z tego dalekosiężnie idących wniosków.
Ale trafiają przez to w pułapki - takie jak małe mikrosegmenty, które są starannie wyselekcjonowane, ale w żaden sposób nie nadają się do użycia. Z drugiej strony, pytają nas dlaczego potrzebujemy tych wszystkich liczb, skoro używamy tylko regresji z kilkoma współczynnikami i zmiennymi.
I to jest trudna sztuka oddzielania istotnych sygnałów od szumu. Istnieje słynne powiedzenie, którego często używamy: „Jeśli torturowałeś dane wystarczająco długo, przyznają się w zasadzie do wszystkiego”.
Więc kiedy znów spotkasz hipsterską dziewczynę, przypomnij sobie przykładowe dane do testowania hipotez - starannie zmienione zgodnie z rozmiarem, definicją i znaczeniem wyników, które są nimi podparte.
Teraz przejedźmy się z naszym ostatecznym bohaterem, Frankiem.
Czego Frank Underwood może Cię nauczyć o kreśleniu danych?
Frank jest pragmatyczny. Każdy, kto kiedykolwiek oglądał „House of Cards” wie, że jedyne wskaźniki, na których mu zależy, to liczby. I tak naprawdę często robimy to samo, gdy analizujemy agregaty lub statystyki.
Staramy się wyobrazić sobie świat za nami. I teraz przejdźmy do tego, jaki ma to efekt.
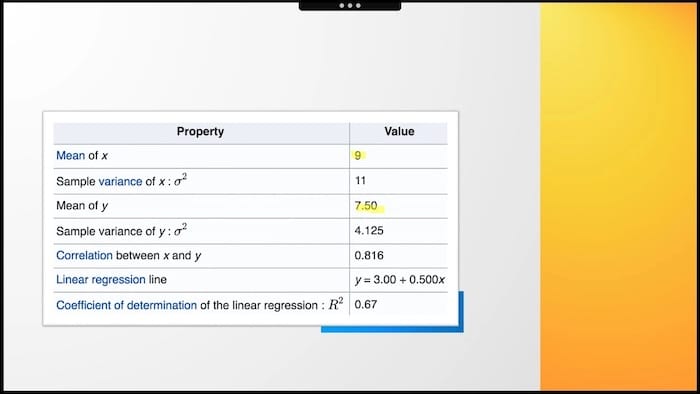
Przeanalizowaliśmy dane paragonowe brytyjskiego sprzedawcy dyskontowego. Ludzie kupują średnio 9 przedmiotów podczas transakcji, wydając siedem i pół funta.
Mamy odchylenia standardowe dla obu zmiennych. Znamy wzór regresji liniowych. Wszystkie właściwości i wartości są dostępne aby opisać to zjawisko, prawda? Więc co to jest? Który wykres jest zdefiniowany przez te wskaźniki?
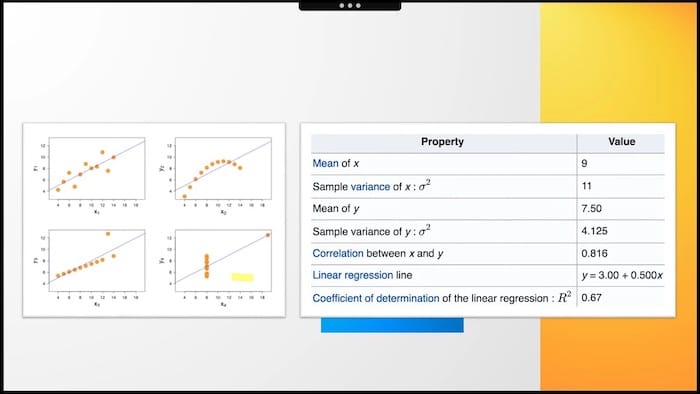
Powiedzmy, że twój szef chce, abyś zwiększył średnią liczbę przedmiotów kupowanych przez klientów do 10. Patrząc na wykres 1 - ten cel wydaje się wykonalny, ale patrząc na wykres 4 - raczej niemożliwy do spełnienia.
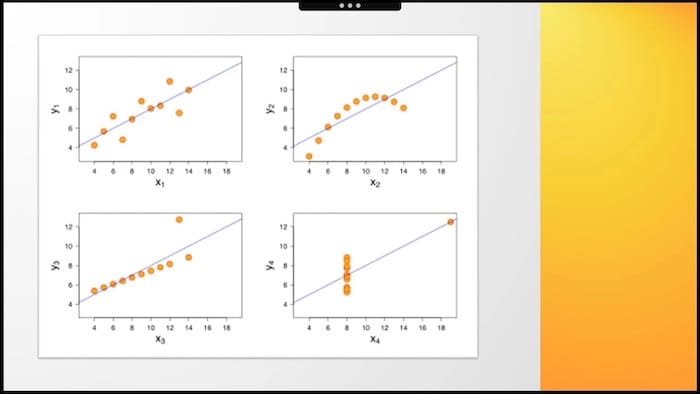
Problem polega na tym, że wszystkie cztery zestawy danych można opisać za pomocą tych samych statystyk. Ale jak widać, patrząc na rozkład danych na wykresach, konfiguracje punktów są zupełnie inne.
Ponownie, jak w przypadku Simpsona, tak naprawdę nie chodzi o naszego przewodnika - Franka Underwooda, ale innego Franka. Nazywał się Frank Anscombe, i w 1973 roku narysował te cztery wykresy, aby przypomnieć nam o znaczeniu sposobów wizualizacji danych.
Więc jeśli jest jedna rzecz, której Frank może cię nauczyć: zawsze staraj się zwizualizować dane. Nie polegaj na statystykach i agregatach.
Podsumowanie
To koniec naszej podróży przez naukę o danych, prowadzonej przez tych trzech bohaterów. Mam nadzieję, że następnym razem, gdy zobaczysz Homera Simpsona, hipsterską dziewczynę lub Franka Underwooda, przypomną ci o następujących kwestiach:
- Trend może się odwrócić. Podczas łączenia danych z grup mogą wystąpić rozbieżności.
- Uważaj na pozornie proste wnioski z małych grup, które próbujesz ekstrapolować na duże grupy.
- Bez względu na wszystko, spróbuj wyrysować dane.
Eksploracja dużych zbiorów danych poprzez analizę danych lojalnościowych może napędzać Twoją markę i umożliwić dostosowanie strategii do wszelkich okoliczności.


